参考:中科大超算中心:Slurm资源管理与作业调度系统安装配置 2021-12 文档
slurm集群安装与踩坑详解
1. Slurm简介
1.1 用途
Slurm(Simple Linux Utility for Resource Management, http://slurm.schedmd.com/ )是开源的、具有容错性和高度可扩展的Linux集群超级计算系统资源管理和作业调度系统。超级计算系统可利用Slurm对资源和作业进行管理,以避免相互干扰,提高运行效率。所有需运行的作业,无论是用于程序调试还是业务计算,都可以通过交互式并行 srun 、批处理式 sbatch 或分配式 salloc 等命令提交,提交后可以利用相关命令查询作业状态等。
1.2 构架
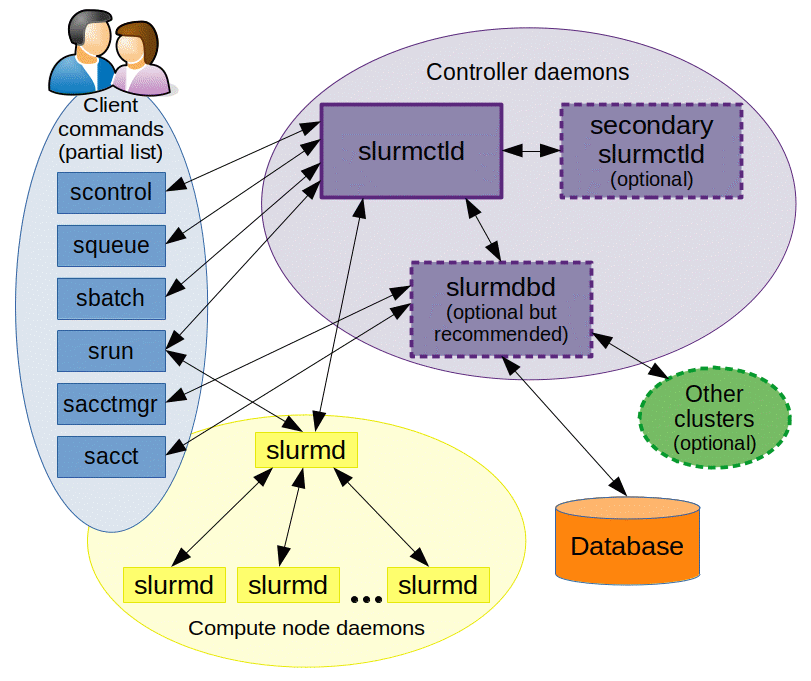
Slurm采用slurmctld服务(守护进程)作为中心管理器用于监测资源和作业,为了提高可用性,还可以配置另一个备份冗余管理器。各计算节点需启动slurmd守护进程,以便被用于作为远程shell使用:等待作业、执行作业、返回状态、再等待更多作业。slurmdbd(Slurm DataBase Daemon)数据库守护进程(非必需,建议采用,也可以记录到纯文本中等),可以将多个slurm管理的集群的记账信息记录在同一个数据库中。还可以启用slurmrestd(Slurm REST API Daemon)服务(非必需),该服务可以通过REST API与Slurm进行交互,所有功能都对应的API。用户工具包含 srun 运行作业、 scancel 终止排队中或运行中的作业、 sinfo 查看系统状态、 squeue 查看作业状态、 sacct 查看运行中或结束了的作业及作业步信息等命令。 sview 命令可以图形化显示系统和作业状态(可含有网络拓扑)。 scontrol 作为管理工具,可以监控、修改集群的配置和状态信息等。用于管理数据库的命令是 sacctmgr ,可认证集群、有效用户、有效记账账户等。
1.3 术语
-
节点
- Hea Node:头节点、管理节点、控制节点,运行slurmctld管理服务的节点。
- Compute Node:计算节点,运行作业计算任务的节点,需运行slurmd服务。
-
Login Node:用户登录节点,用于用户登录的节点。
-
SlurmDBD Node:SlurmDBD节点、SlurmDBD数据库节点,存储调度策略、记账和作业等信息的节点,需运行slurmdbd服务。
- 客户节点:含计算节点和用户登录节点。
- 用户
-
account:账户,一个账户可以含有多个用户。
-
user:用户,多个用户可以共享一个账户。
-
bank account:银行账户,对应机时费等。
-
- 资源
-
GRES:Generic Resource,通用资源。
-
TRES:Trackable RESources,可追踪资源。
-
QOS:Quality of Service,服务质量,作业优先级。
-
association:关联。可利用其实现,如用户的关联不在数据库中,这将阻止用户运行作业。该选项可以阻止用户访问无效账户。
-
Partition:队列、分区。用于对计算节点、作业并行规模、作业时长、用户等进行分组管理,以合理分配资源。
-
1.4 插件
Slurm含有一些通用目的插件可以使用,采用这些插件可以方便地支持多种基础结构,允许利用构建块方式吸纳多种Slurm配置,主要包括如下插件:
-
记账存储(Accounting Storage):主要用于存储作业历史数据。当采用SlurmDBD时,可以支持有限的基于系统的历史系统状态。
-
账户收集能源(Account Gather Energy):收集系统中每个作业或节点的能源(电力)消耗,该插件与记账存储Accounting Storage和作业记账收集Job Account Gather插件一起使用。
-
通信认证(Authentication of communications):提供在Slurm不同组件之间进行认证机制。
-
容器(Containers):HPC作业负载容器支持及实现。
-
信用(Credential,数字签名生成,Digital Signature Generation):用于生成电子签名的机制,可用于验证作业步在某节点上具有执行权限。与用于身份验证的插件不同,因为作业步请求从用户的 srun 命令发送,而不是直接从slurmctld守护进程发送,该守护进程将生成作业步凭据及其数字签名。
-
通用资源(Generic Resources):提供用于控制通用资源(如GPU)的接口。
-
作业提交(Job Submit):该插件提供特殊控制,以允许站点覆盖作业在提交和更新时提出的需求。
-
作业记账收集(Job Accounting Gather):收集作业步资源使用数据。
-
作业完成记录(Job Completion Logging):记录作业完成数据,一般是记账存储插件的子数据集。
-
启动器(Launchers):控制srun启动任务时的机制。
-
MPI:针对多种MPI实现提供不同钩子,可用于设置MPI环境变量等。
-
抢占(Preempt):决定哪些作业可以抢占其它作业以及所采用的抢占机制。
-
优先级(Priority):在作业提交时赋予作业优先级,且在运行中生效(如,它们生命期)。
-
进程追踪(Process tracking,为了信号控制):提供用于确认各作业关联的进程,可用于作业记账及信号控制。
-
调度器(Scheduler):用于决定Slurm何时及如何调度作业的插件。
-
节点选择(Node selection):用于决定作业分配的资源插件。
-
站点因子(Site Factor,站点优先级):将作业多因子组件中的特殊的site_factor优先级在作业提交时赋予作业,且在运行中生效(如,它们生命期)。
-
交换及互联(Switch or interconnect):用于网络交换和互联接口的插件。对于多数网络系统(以太网或InifiniBand)并不需要。
-
作业亲和性(Task Affinity):提供一种用于将作业和其独立的任务绑定到特定处理器的机制。
-
网络拓扑(Network Topology):基于网络拓扑提供资源选择优化,用于作业分配和提前预留资源。
2 规划准备
-
集群名:MyCluster
-
管理节点: xhpc
-
内网IP:127.0.0.1
-
配置文件: /opt/slurm/22.05.5/etc 目录下的 cgroup.conf 、 slurm.conf 、 slurmdbd.conf 等文件
-
需要启动(按顺序)的守护进程服务:
-
通信认证:munge
-
系统数据库:mariadb(也可采用文本保存,更简单,本文不涉及)
-
Slurm数据库:slurmdbd
- 主控管理器:slurmctld
-
- 数据库节点(运行slurmdbd服务)xhpc:
- 用户登录节点xhpc
- 计算节点xhpc
- 需要启动(按顺序)的服务:
通信认证:munge
Slurm数据库:slurmdbd
管理节点建立slurm用户后,各计算节点执行
id slurm可确认其slurm用户是否存在
- 需要启动(按顺序)的服务:
通信认证:munge
Slurm数据库:slurmdbd
管理节点建立slurm用户后,各计算节点执行
- 管理服务的常用命令(以slurmd为例):
-
设置开机自启动服务: systemctl enable slurmd
-
启动服务: systemctl start slurmd
-
重新启动服务: systemctl restart slurmd
-
停止服务: systemctl stop slurmd
-
查看服务状态及出错信息: systemctl status slurmd
-
查看服务日志: journalctl -xe
-
3 安装munge
munge是认证服务,用于生成和验证证书。应用于大规模的HPC集群中。它允许进程在【具有公用的用户和组的】主机组中,对另外一个【本地或者远程的】进程的UID和GID进行身份验证。这些主机构成由共享密钥定义的安全领域。在此领域中的客户端能够在不使用root权限,不保留端口,或其他特定平台下进行创建凭据和验证。简而言之,在集群中,munge能够实现本地或者远程主机进程的GID和UID验证。
munge提供组件间的认证通信机制,这个需要在所有节点安装并且启动。munge为slurm默认的验证机制,各节点 /etc/munge/munge.key 的内容需要一致,且所有者都为munge用户。
ls -lha /etc/munge/munge.key
munge用户查看:
1
id munge
1
2
3
systemctl enable munge # 设置munge开机自启动
systemctl start munge # 启动munge服务
systemctl status munge # 查看munge状态
4 编译安装slurm
可以采用第三方已编译好的RPM或DEB包进行安装,也可以采用源码编译方式,本方法采用源码包进行安装。
4.1 安装编译slurm所需的依赖包
1
2
3
4
5
6
7
8
9
10
11
sudo apt update
sudo apt upgrade
sudo -i #进入root用户
#slrum要进行munge密钥认证,所以要先安装munge并生成密钥
apt install munge libmunge-dev libmunge2 # 安装用户权限管理 munge
# 安装slurmdbd的数据库支持mysql,目前最新版一般都是mysql8了
apt install libmysql++-dev mysql-server mysql-client libmysqlclient-dev
# 安装mariadb
apt install mariadb-client mariadb-server libmariadb-dev
#安装其他依赖库
apt install make cmake git build-essential libssl-dev ffmpeg openssh-server hwloc libevent-dev libhwloc-dev libhdf5-dev -y
4.2 下载Slurm源码包安装
访问 ttps://www.schedmd.com/downloads.php 复制所需版本下载源码包链接后,执行:
1
2
3
4
5
6
7
cd /root/softpackages/slurm
wget https://download.schedmd.com/slurm/slurm-22.05.6.tar.bz2
tar -jxvf slurm-22.05.6.tar.bz2
cd slurm-22.05.6
./configure --prefix=/opt/slurm/22.05.6 --sysconfdir=/opt/slurm/22.05.6/etc
make -j16
make install
添加环境变量,bash 全局的话可以放在
1
vim /etc/profile.d/slurm.sh
添加:
1
2
3
4
5
export SLURM_HOME=/opt/slurm/22.05.6
export PATH=$SLURM_HOME/bin:$PATH
export PATH=$SLURM_HOME/sbin:$PATH
export LD_LIBRARY_PATH=$SLURM_HOME/lib:$LD_LIBRARY_PATH
export LD_LIBRARY_PATH=$SLURM_HOME/lib/slurm:$LD_LIBRARY_PATH
或者修改/etc/bash.bashrc
1
2
3
SLURMPATH=/opt/slurm/22.05.6
echo "export PATH=\$PATH:$SLURMPATH/bin:$SLURMPATH/sbin" >> /etc/bash.bashrc
source /etc/bash.bashrc
4.3 生成slurm用户
Slurm需要有一个用户用于进行通信、认证等操作,这里用户名为slurm(也可为其它名字):
- 生成用户,执行:
1
useradd slurm
- 其它节点配置有NIS或LDAP等用户信息管理系统,自动从管理节点获取slurm用户信息(无需再单独生成slurm用户),执行以下命令确认是否存在(如未存在,请检查相关服务):
1
pdsh -w node[1-10],login id slurm
4.4 配置
包含MySQL数据库,mariadb,slurm以及slurmdb配置文件
4.4.1 配置mariadb数据库
接下来配置 slurmdbd 需要的数据库
先修改/etc/mysql/my.cnf,添加:
1
2
3
4
[mysqld]
innodb_buffer_pool_size=1024M
innodb_log_file_size=64M
innodb_lock_wait_timeout=900
然后启动mysql,并设置开机自启
1
2
3
4
5
# 然后启动mysql,并设置开机自启,如果只是开: sudo systemctl start mysql
sudo systemctl enable --now mysql
# 进入mysql,默认root的mysql没有密码,不建议设置
sudo mysql
创建 slurm 单独的用户和需要的数据库
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 创建slurm单独的mysql用户,只本地访问即可,以便该用户操作slurm_acct_db数据库,其密码是SomePassWD
create user 'slurm'@'localhost' identified by 'SomePassWD';
# 创建基础数据库,生成账户数据库slurm_acct_db
create database slurm_acct_db;
# 赋予slurm用户从本机localhost采用密码SomePassWD登录具备操作slurm_acct_db数据下所有表的全部权限
#grant all on slurm_acct_db.* TO 'slurm'@'localhost';
grant all on slurm_acct_db.* TO 'slurm'@'localhost' identified by 'SomePassWD' with grant option;
# 生成作业信息数据库slurm_jobcomp_db
create database slurm_jobcomp_db;
# 赋予slurm从本机localhost采用密码SomePassWD登录具备操作slurm_jobcomp_db数据下所有表的全部权限
grant all on slurm_jobcomp_db.* TO 'slurm'@'localhost' identified by 'SomePassWD' with grant option;
# 创建另一个,这个不强制,但是建议,如果不创建,后面slurm配置需要改,所以还是创建吧
create database slurm_job_db;
grant all on slurm_job_db.* TO 'slurm'@'localhost';
exit;
下面的不要输入,但是有兴趣学习 mysql 可以入门
1
2
3
4
5
6
7
8
9
10
11
12
13
# 删除用户libmariadb-devel
# 查看有哪些数据库
show databases;
# 查看某个数据库的表格
use slurm_acct_db;
# 查看某个表格的杰哥
describe 表格名字;
# 删除数据库和数据表
drop database 数据库名;
drop table 数据表名;
4.4.2 设置主配置文件slurm.conf
Slurm配置文件主要在/opt/slurm/22.05.6/etc目录下,由Slurm安装时设置,默认在 /etc/slurm/ 目录下
配置文件可以从官网 Slurm System Configuration Tool 进行自动生成,也可以采用源码包etc目录下的模板进行修改
1
2
3
4
cp etc/slurm.conf.example /opt/slurm/22.05.6/etc/slurm.conf
cp etc/cgroup.conf.example /opt/slurm/22.05.6/etc/cgroup.conf
cp etc/slurmdbd.conf.example /opt/slurm/22.05.6/etc/slurmdbd.conf
chmod 600 /opt/slurm/22.05.6/etc/*.conf
主配置文件:/opt/slurm/22.05.6/etc/slurm.conf
对其进行修改:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
# Cluster Name:集群名
ClusterName=MyCluster # 集群名,任意英文和数字名字
# Control Machines:Slurmctld控制进程节点
SlurmctldHost=localhost # 启动slurmctld进程的节点名,如这里的admin 单机用 localhost即可
BackupController= # 冗余备份节点,可空着
SlurmctldParameters=enable_configless # 采用无配置模式
# Slurm User:Slurm用户
SlurmUser=slurm # slurmctld启动时采用的用户名
# SlurmUser=root #为了避免文件权限的问题,建议设置为root
# Slurm Port Numbers:Slurm服务通信端口
SlurmctldPort=6817 # Slurmctld服务端口,设为6817,如不设置,默认为6817号端口
SlurmdPort=6818 # Slurmd服务端口,设为6818,如不设置,默认为6818号端口
# State Preservation:状态保持
StateSaveLocation=/var/spool/slurmctld # 存储slurmctld服务状态的目录,如有备份控制节点,则需要所有SlurmctldHost节点都能共享读写该目录
SlurmdSpoolDir=/var/spool/slurmd # Slurmd服务所需要的目录,为各节点各自私有目录,不得多个slurmd节点共享
ReturnToService=1 #设定当DOWN(失去响应)状态节点如何恢复服务,默认为0。
# 0: 节点状态保持DOWN状态,只有当管理员明确使其恢复服务时才恢复
# 1: 仅当由于无响应而将DOWN节点设置为DOWN状态时,才可以当有效配置注册后使DOWN节点恢复服务。如节点由于任何其它原因(内存不足、意外重启等)被设置为DOWN,其状态将不会自动更改。当节点的内存、GRES、CPU计数等等于或大于slurm.conf中配置的值时,该节点才注册为有效配置。
# 2: 使用有效配置注册后,DOWN节点将可供使用。该节点可能因任何原因被设置为DOWN状态。当节点的内存、GRES、CPU计数等等于或大于slurm.conf 中配置的值,该节点才注册为有效配置。
# Default MPI Type:默认MPI类型
MPIDefault=None
# mpi-pmi2: 对支持PMI2的MPI实现
# mpi-pmix: Exascale PMI实现
# none: 对于大多数其它MPI,建议设置
# Process Tracking:进程追踪,定义用于确定特定的作业所对应的进程的算法,它使用信号、杀死和记账与作业步相关联的进程
ProctrackType=proctrack/cgroup
# Cgroup: 采用Linux cgroup来生成作业容器并追踪进程,需要设定/etc/slurm/cgroup.conf文件
# Cray XC: 采用Cray XC专有进程追踪
# LinuxProc: 采用父进程IP记录,进程可以脱离Slurm控制
# Pgid: 采用Unix进程组ID(Process Group ID),进程如改变了其进程组ID则可以脱离Slurm控制
# Scheduling:调度
# DefMemPerCPU=0 # 默认每颗CPU可用内存,以MB为单位,0为不限制。如果将单个处理器分配给作业(SelectType=select/cons_res 或 SelectType=select/cons_tres),通常会使用DefMemPerCPU
# MaxMemPerCPU=0 # 最大每颗CPU可用内存,以MB为单位,0为不限制。如果将单个处理器分配给作业(SelectType=select/cons_res 或 SelectType=select/cons_tres),通常会使用MaxMemPerCPU
# SchedulerTimeSlice=30 # 当GANG调度启用时的时间片长度,以秒为单位
SchedulerType=sched/backfill # 要使用的调度程序的类型。注意,slurmctld守护程序必须重新启动才能使调度程序类型的更改生效(重新配置正在运行的守护程序对此参数无效)。如果需要,可以使用scontrol命令手动更改作业优先级。可接受的类型为:
# sched/backfill # 用于回填调度模块以增加默认FIFO调度。如这样做不会延迟任何较高优先级作业的预期启动时间,则回填调度将启动较低优先级作业。回填调度的有效性取决于用户指定的作业时间限制,否则所有作业将具有相同的时间限制,并且回填是不可能的。注意上面SchedulerParameters选项的文档。这是默认配置
# sched/builtin # 按优先级顺序启动作业的FIFO调度程序。如队列中的任何作业无法调度,则不会调度该队列中优先级较低的作业。对于作业的一个例外是由于队列限制(如时间限制)或关闭/耗尽节点而无法运行。在这种情况下,可以启动较低优先级的作业,而不会影响较高优先级的作业。
# sched/hold # 如果 /etc/slurm.hold 文件存在,则暂停所有新提交的作业,否则使用内置的FIFO调度程序。
# Resource Selection:资源选择,定义作业资源(节点)选择算法
SelectType=select/cons_tres
# select/cons_tres: 单个的CPU核、内存、GPU及其它可追踪资源作为可消费资源(消费及分配),建议设置
# select/cons_res: 单个的CPU核和内存作为可消费资源
# select/cray_aries: 对于Cray系统
# select/linear: 基于主机的作为可消费资源,不管理单个CPU等的分配
# SelectTypeParameters:资源选择类型参数,当SelectType=select/linear时仅支持CR_ONE_TASK_PER_CORE和CR_Memory;当SelectType=select/cons_res、SelectType=select/cray_aries和SelectType=select/cons_tres时,默认采用CR_Core_Memory
SelectTypeParameters=CR_Core_Memory
# CR_CPU: CPU核数作为可消费资源
# CR_Socket: 整颗CPU作为可消费资源
# CR_Core: CPU核作为可消费资源,默认
# CR_Memory: 内存作为可消费资源,CR_Memory假定MaxShare大于等于1
# CR_CPU_Memory: CPU和内存作为可消费资源
# CR_Socket_Memory: 整颗CPU和内存作为可消费资源
# CR_Core_Memory: CPU和和内存作为可消费资源
# Task Launch:任务启动
TaskPlugin=task/cgroup,task/affinity #设定任务启动插件。可被用于提供节点内的资源管理(如绑定任务到特定处理器),TaskPlugin值可为:
# task/affinity: CPU亲和支持(man srun查看其中--cpu-bind、--mem-bind和-E选项)
# task/cgroup: 强制采用Linux控制组cgroup分配资源(man group.conf查看帮助)
# task/none: #无任务启动动作
# Prolog and Epilog:前处理及后处理
# Prolog/Epilog: 完整的绝对路径,在用户作业开始前(Prolog)或结束后(Epilog)在其每个运行节点上都采用root用户执行,可用于初始化某些参数、清理作业运行后的可删除文件等
# Prolog=/opt/bin/prolog.sh # 作业开始运行前需要执行的文件,采用root用户执行
# Epilog=/opt/bin/epilog.sh # 作业结束运行后需要执行的文件,采用root用户执行
# SrunProlog/Epilog # 完整的绝对路径,在用户作业步开始前(SrunProlog)或结束后(Epilog)在其每个运行节点上都被srun执行,这些参数可以被srun的--prolog和--epilog选项覆盖
# SrunProlog=/opt/bin/srunprolog.sh # 在srun作业开始运行前需要执行的文件,采用运行srun命令的用户执行
# SrunEpilog=/opt/bin/srunepilog.sh # 在srun作业结束运行后需要执行的文件,采用运行srun命令的用户执行
# TaskProlog/Epilog: 绝对路径,在用户任务开始前(Prolog)和结束后(Epilog)在其每个运行节点上都采用运行作业的用户身份执行
# TaskProlog=/opt/bin/taskprolog.sh # 作业开始运行前需要执行的文件,采用运行作业的用户执行
# TaskEpilog=/opt/bin/taskepilog.sh # 作业结束后需要执行的文件,采用运行作业的用户执行行
# 顺序:
# 1. pre_launch_priv():TaskPlugin内部函数
# 2. pre_launch():TaskPlugin内部函数
# 3. TaskProlog:slurm.conf中定义的系统范围每个任务
# 4. User prolog:作业步指定的,采用srun命令的--task-prolog参数或SLURM_TASK_PROLOG环境变量指定
# 5. Task:作业步任务中执行
# 6. User epilog:作业步指定的,采用srun命令的--task-epilog参数或SLURM_TASK_EPILOG环境变量指定
# 7. TaskEpilog:slurm.conf中定义的系统范围每个任务
# 8. post_term():TaskPlugin内部函数
# Event Logging:事件记录
# Slurmctld和slurmd守护进程可以配置为采用不同级别的详细度记录,从0(不记录)到7(极度详细)
SlurmctldDebug=info # 默认为info
SlurmctldLogFile=/var/log/slurm/slurmctld.log # 如是空白,则记录到syslog
SlurmdDebug=info # 默认为info
SlurmdLogFile=/var/log/slurm/slurmd.log # 如为空白,则记录到syslog,如名字中的有字符串"%h",则"%h"将被替换为节点名
# Job Completion Logging:作业完成记录
JobCompType=jobcomp/mysql
# 指定作业完成是采用的记录机制,默认为None,可为以下值之一:
# None: 不记录作业完成信息
# Elasticsearch: 将作业完成信息记录到Elasticsearch服务器
# FileTxt: 将作业完成信息记录在一个纯文本文件中
# Lua: 利用名为jobcomp.lua的文件记录作业完成信息
# Script: 采用任意脚本对原始作业完成信息进行处理后记录
# MySQL: 将完成状态写入MySQL或MariaDB数据库
# JobCompLoc= # 设定记录作业完成信息的文本文件位置(若JobCompType=filetxt),或将要运行的脚本(若JobCompType=script),或Elasticsearch服务器的URL(若JobCompType=elasticsearch),或数据库名字(JobCompType为其它值时)
# 设定数据库在哪里运行,且如何连接
JobCompHost=localhost # 存储作业完成信息的数据库主机名
# JobCompPort= # 存储作业完成信息的数据库服务器监听端口
JobCompUser=slurm # 用于与存储作业完成信息数据库进行对话的用户名
JobCompPass=SomePassWD # 用于与存储作业完成信息数据库进行对话的用户密码
# Job Accounting Gather:作业记账收集
JobAcctGatherType=jobacct_gather/linux # Slurm记录每个作业消耗的资源,JobAcctGatherType值可为以下之一:
# jobacct_gather/none: 不对作业记账
# jobacct_gather/cgroup: 收集Linux cgroup信息
# jobacct_gather/linux: 收集Linux进程表信息,建议
JobAcctGatherFrequency=30 # 设定轮寻间隔,以秒为单位。若为-,则禁止周期性抽样
# Job Accounting Storage:作业记账存储
AccountingStorageType=accounting_storage/slurmdbd # 与作业记账收集一起,Slurm可以采用不同风格存储可以以许多不同的方式存储会计信息,可为以下值之一:
# accounting_storage/none: 不记录记账信息
# accounting_storage/slurmdbd: 将作业记账信息写入Slurm DBD数据库
# AccountingStorageLoc: 设定文件位置或数据库名,为完整绝对路径或为数据库的数据库名,当采用slurmdb时默认为slurm_acct_db
# 设定记账数据库信息,及如何连接
AccountingStorageHost=localhost # 记账数据库主机名
# AccountingStoragePort= # 记账数据库服务监听端口
# AccountingStorageUser=slurm # 记账数据库用户名
# AccountingStoragePass=SomePassWD # 记账数据库用户密码。对于SlurmDBD,提供企业范围的身份验证,如采用于Munge守护进程,则这是应该用munge套接字socket名(/var/run/munge/global.socket.2)代替。默认不设置
# AccountingStoreFlags= # 以逗号(,)分割的列表。选项是:
# job_comment:在数据库中存储作业说明域
# job_script:在数据库中存储脚本
# job_env:存储批处理作业的环境变量
# AccountingStorageTRES=gres/gpu # 设置GPU时需要
# GresTypes=gpu # 设置GPU时需要
# Process ID Logging:进程ID记录,定义记录守护进程的进程ID的位置
SlurmctldPidFile=/var/run/slurmctld.pid # 存储slurmctld进程号PID的文件
SlurmdPidFile=/var/run/slurmd.pid # 存储slurmd进程号PID的文件
# Timers:定时器
SlurmctldTimeout=120 # 设定备份控制器在主控制器等待多少秒后成为激活的控制器
SlurmdTimeout=300 # Slurm控制器等待slurmd未响应请求多少秒后将该节点状态设置为DOWN
InactiveLimit=0 # 潜伏期控制器等待srun命令响应多少秒后,将在考虑作业或作业步骤不活动并终止它之前。0表示无限长等待
MinJobAge=300 # Slurm控制器在等待作业结束多少秒后清理其记录
KillWait=30 # 在作业到达其时间限制前等待多少秒后在发送SIGKILLL信号之前发送TERM信号以优雅地终止
WaitTime=0 # 在一个作业步的第一个任务结束后等待多少秒后结束所有其它任务,0表示无限长等待
# Compute Machines:计算节点
NodeName=node[1-10] NodeAddr=192.168.1.[1-8] CPUs=48 RealMemory=192000 Sockets=2 CoresPerSocket=24 ThreadsPerCore=1 State=UNKNOWN
# NodeName=gnode[01-10] Gres=gpu:v100:2 CPUs=40 RealMemory=385560 Sockets=2 CoresPerSocket=20 ThreadsPerCore=1 State=UNKNOWN #GPU节点例子,主要为Gres=gpu:v100:2
# NodeName=node[1-10] # 计算节点名,node[1-10]表示为从node1、node2连续编号到node10,其余类似
# NodeAddr=192.168.1.[1-10] # 计算节点IP
# CPUs=48 # 节点内CPU核数,如开着超线程,则按照2倍核数计算,其值为:Sockets*CoresPerSocket*ThreadsPerCore
# RealMemory=192000 # 节点内作业可用内存数(MB),一般不大于free -m的输出,当启用select/cons_res插件限制内存时使用
# Sockets=2 # 节点内CPU颗数
# CoresPerSocket=24 # 每颗CPU核数
# ThreadsPerCore=1 # 每核逻辑线程数,如开了超线程,则为2
# State=UNKNOWN # 状态,是否启用,State可以为以下之一:
# CLOUD # 在云上存在
# DOWN # 节点失效,不能分配给在作业
# DRAIN # 节点不能分配给作业
# FAIL # 节点即将失效,不能接受分配新作业
# FAILING # 节点即将失效,但上面有作业未完成,不能接收新作业
# FUTURE # 节点为了将来使用,当Slurm守护进程启动时设置为不存在,可以之后采用scontrol命令简单地改变其状态,而不是需要重启slurmctld守护进程。当这些节点有效后,修改slurm.conf中它们的State。在它们被设置为有效前,采用Slurm看不到它们,也尝试与其联系。
# 动态未来节点(Dynamic Future Nodes):
# slurmd启动时如有-F[<feature>]参数,将关联到一个与slurmd -C命令显示配置(sockets、cores、threads)相同的配置的FUTURE节点。节点的NodeAddr和NodeHostname从slurmd守护进程自动获取,并且当被设置为FUTURE状态后自动清除。动态未来节点在重启时保持non-FUTURE状态。利用scontrol可以将其设置为FUTURE状态。
# 若NodeName与slurmd的HostName映射未通过DNS更新,动态未来节点不知道在之间如何进行通信,其原因在于NodeAddr和NodeHostName未在slurm.conf被定义,而且扇出通信(fanout communication)需要通过将TreeWidth设置为一个较高的数字(如65533)来使其无效。若做了DNS映射,则可以使用cloud_dns SlurmctldParameter。
# UNKNOWN # 节点状态未被定义,但将在节点上启动slurmd进程后设置为BUSY或IDLE,该为默认值。
PartitionName=batch Nodes=node[1-10] Default=YES MaxTime=INFINITE State=UP
# PartitionName=batch # 队列分区名
# Nodes=node[1-10] # 节点名
# Default=Yes # 作为默认队列,运行作业不知明队列名时采用的队列
# MaxTime=INFINITE # 作业最大运行时间,以分钟为单位,INFINITE表示为无限制
# State=UP # 状态,是否启用
# Gres=gpu:v100:2 # 设置节点有两块v100 GPU卡,需要在GPU节点 /etc/slum/gres.conf 文件中有类似下面配置:
#AutoDetect=nvml
Name=gpu Type=v100 File=/dev/nvidia[0-1] #设置资源的名称Name是gpu,类型Type为v100,名称与类型可以任意取,但需要与其它方面配置对应,File=/dev/nvidia[0-1]指明了使用的GPU设备。
#Name=mps Count=100
4.4.3 数据存储方式配置文件 slurmdbd.conf
详细可以看 官网 slurmdbd.conf
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
ArchiveEvents=yes
ArchiveJobs=yes
ArchiveResvs=yes
ArchiveSteps=no
ArchiveSuspend=no
ArchiveTXN=no
ArchiveUsage=no
AuthInfo=/usr/local/munge/var/run/munge/munge.socket.2
AuthType=auth/munge
DbdHost=localhost
DebugLevel=info
PurgeEventAfter=1month
PurgeJobAfter=12month
PurgeResvAfter=1month
PurgeStepAfter=1month
PurgeSuspendAfter=1month
PurgeTXNAfter=12month
PurgeUsageAfter=24month
LogFile=/var/log/slurmdbd.log
PidFile=/var/run/slurmdbd.pid
SlurmUser=root
StoragePass=SomePassWD
StorageType=accounting_storage/mysql
StorageUser=slurm
StorageHost=localhost
StoragePort=3306
上面的配置直接复制的官网的,不同版本 slurm 有区别,如下的关键词需要注意
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 认证方式,该处采用munge进行认证
AuthType=auth/munge
# 为了与slurmctld控制节点通信的其它认证信息
AuthInfo=/var/run/munge/munge.socket.2
# slurmDBD信息
DbdHost=localhost # 数据库节点名,这个就行,因为slurmdbdb只在master上
DbdAddr=127.0.0.1 # 数据库IP地址
SlurmUser=slurm #用户数据库操作的用户
DebugLevel=debug5 # 调试信息级别,quiet:无调试信息;fatal:仅严重错误信息;error:仅错误信息; info:错误与通常信息;verbose:错误和详细信息;debug:错误、详细和调试信息;debug2:错误、详细和更多调试信息;debug3:错误、详细和甚至更多调试信息;debug4:错误、详细和甚至更多调试信息;debug5:错误、详细和甚至更多调试信息。debug数字越大,信息越详细
DefaultQOS=normal # 默认QOS
LogFile=/var/log/slurm/slurmdbd.log # slurmdbd守护进程日志文件绝对路径
PidFile=/var/run/slurmdbd.pid # slurmdbd守护进程存储进程号文件绝对路径
# Database信息,详细解释参见前面slurm.conf中的
StorageType=accounting_storage/mysql # 数据存储类型
StorageHost=localhost # 存储数据库节点名
StorageLoc=slurm_acct_db # 存储位置
StoragePort=3306 # 存储数据库服务端口号
StorageUser=slurm # 存储数据库用户名
StoragePass=SomePassWD # 存储数据库密码
5.开启守护进程并设置开机自启
5.1 先开启 munge
1
2
3
systemctl enable munge # 设置munge开机自启动
systemctl start munge # 启动munge服务
systemctl status munge # 查看munge状态
5.2 开启mariadb服务
1
2
3
systemctl enable mariadb # 设置mariadb开机自启动
systemctl start mariadb # 启动mariadb服务
systemctl status mariadb # 查看mariadb状态
5.3 开启slurmdbd
1
2
3
systemctl enable slurmdbd # 设置slurmdbd开机自启动
systemctl start slurmdbd # 启动slurmdbd服务
systemctl status slurmdbd # 查看slurmdbd状态
5.4 开启slurmctld
1
2
3
systemctl enable slurmctld # 设置slurmctld开机自启动
systemctl start slurmctld # 启动slurmctld服务
systemctl status slurmctld # 查看slurmctld状态
5.5 开启slurmd
1
2
3
systemctl enable slurmd # 设置slurmd开机自启动
systemctl start slurmd # 启动slurmd服务
systemctl status slurmd # 查看slurmd状态
5.6 打开开机自启
1
2
3
4
5
systemctl enable munge
systemctl enable mariadb
systemctl enable slurmdbd
systemctl enable slurmctld
systemctl enable slurmd
完成后使用sinfo查看队列情况
1
2
3
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
debug* up infinite 1 idle localhost